win11下docker安装chinese Clip的教程
自己的数据集里中文为主。虽然原生clip居然也能处理中文,不过github上也有个chinese clip,据说使用大规模中文数据进行训练(~2亿图文对),旨在帮助用户快速实现中文领域的图文特征&相似度计算、跨模态检索、零样本图片分类等任务。所以我有必要再部署一个chinese clip试一试效果,甚至finetune一下。以下是部署流程。
前置通用步骤
在 PowerShell 中运行以下格式命令,以启用GPU的方式启动容器:docker run –name [给你的容器起的名字] –gpus all -it [你下载的ubuntu镜像ID或名字] /bin/bash
docker run –name chineseClip –gpus all -it ubuntu /bin/bash
接下来更新apt
apt-get update
然后装个wget方便下载其他各种安装包
apt-get install wget
安装Miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-py37_23.1.0-1-Linux-x86_64.sh
bash Miniconda3-py37_23.1.0-1-Linux-x86_64.sh
然后关闭当前终端,重新打开一个新终端,miniconda才能生效。打开新终端,输入以下命令即可
docker exec -it [你的容器名称] /bin/bash
此时可以查看版本号命令来查看miniconda是否已经正确安装。
conda –version
python –version
如果以上命令执行无误,则可以删除之前的miniconda安装脚本
rm Miniconda3-py37_23.1.0-1-Linux-x86_64.sh
更新miniconda
conda install –channel defaults conda python=3.7 –yesconda update –channel defaults –all –yes
更新pip
pip install –upgrade pip
安装chinese Clip
按照GitHub上chinese clip项目的使用说明进行操作:https://github.com/OFA-Sys/Chinese-CLIP
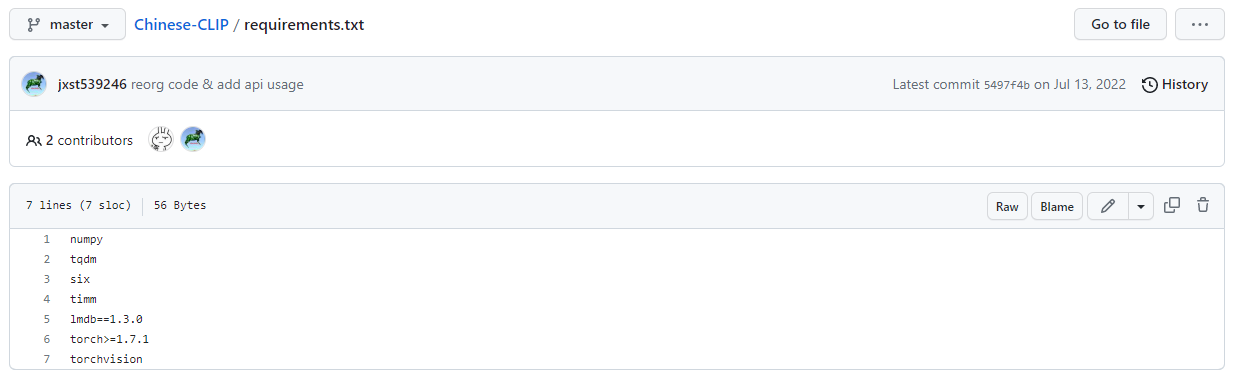
pip install -r requirements.txt
 然后安装cn_clip
然后安装cn_clipChinese Clip模型的使用测试
在宿主机创建一个名为test_clip.py的文件,其中包含代码如下:
import torch
from PIL import Imageimport cn_clip.clip as clip
from cn_clip.clip import load_from_name, available_models
print(“Available models:”, available_models())
# Available models: [‘ViT-B-16’, ‘ViT-L-14’, ‘ViT-L-14-336’, ‘ViT-H-14’, ‘RN50′]device = “cuda” if torch.cuda.is_available() else “cpu”
model, preprocess = load_from_name(“ViT-B-16”, device=device, download_root=’./’)
model.eval()
image = preprocess(Image.open(“test.jpeg”)).unsqueeze(0).to(device)
text = clip.tokenize([“市场”, “工地”, “人”, “狗”, “鱼”, “虾”, “蟹”]).to(device)with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)# 对特征进行归一化,请使用归一化后的图文特征用于下游任务
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)logits_per_image, logits_per_text = model.get_similarity(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()print(“Label probs:”, probs) # [[1.268734e-03 5.436878e-02 6.795761e-04 9.436829e-01]]
然后再找个图片,重命名为test.jpg,比如这个:

然后把test_clip.py和example.jpg都放到一个test文件夹里,然后import到我的linux子系统中。具体的说,我上传到了opt目录下。
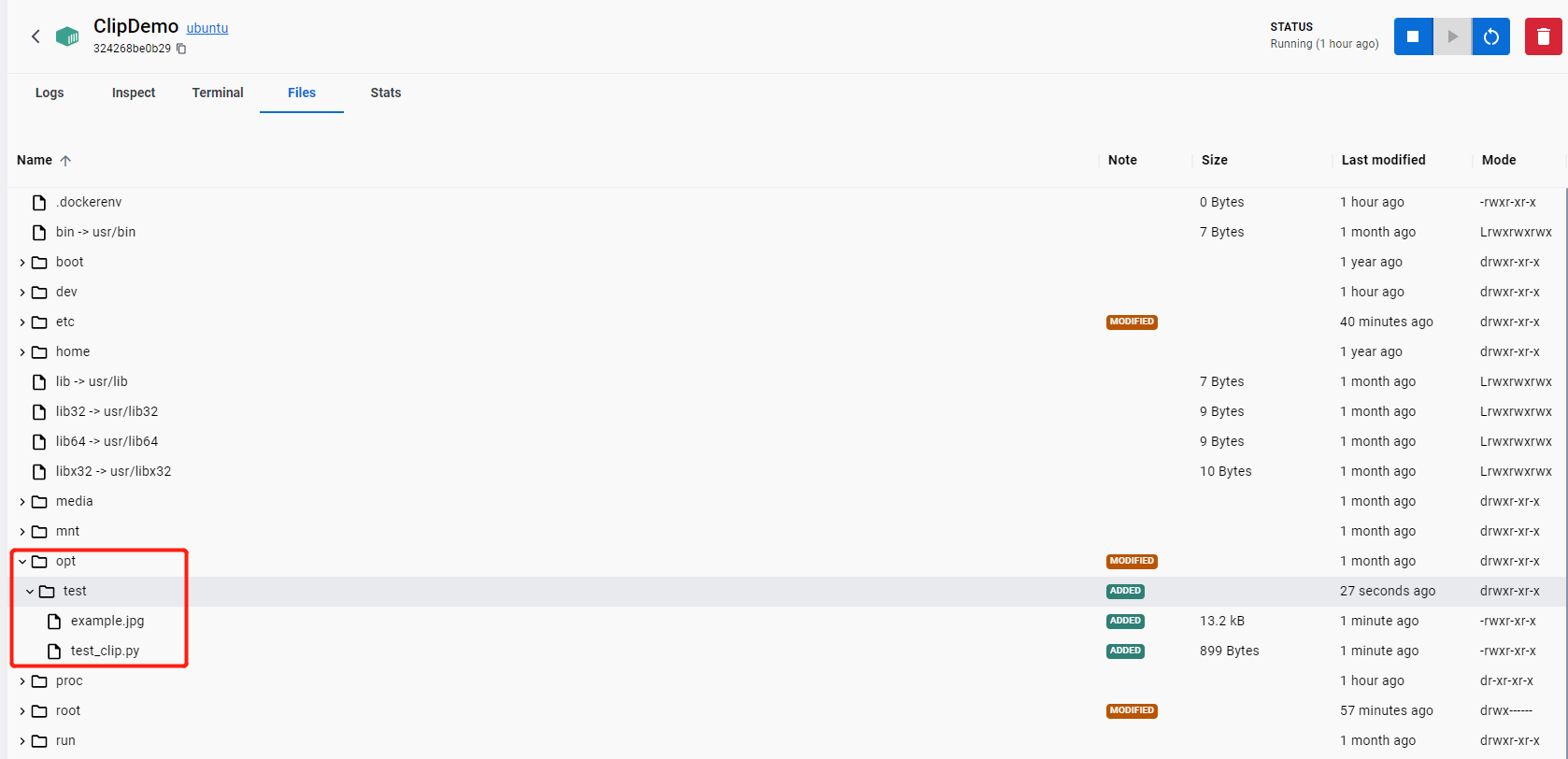
然后回到linux子系统的终端,进入该目录,并运行python文件
cd opt/test
python test_clip.py
返回结果如下:

显示以上内容说明运行成功。上面那些8.877e-01之类的都是科学计数法表示的数字,例如8.877e-01相当于0.8877,对应市场这个词的概率,是几个标签(”市场”, “工地”, “人”, “狗”, “鱼”, “虾”, “蟹”)中与图片相似度最高的。
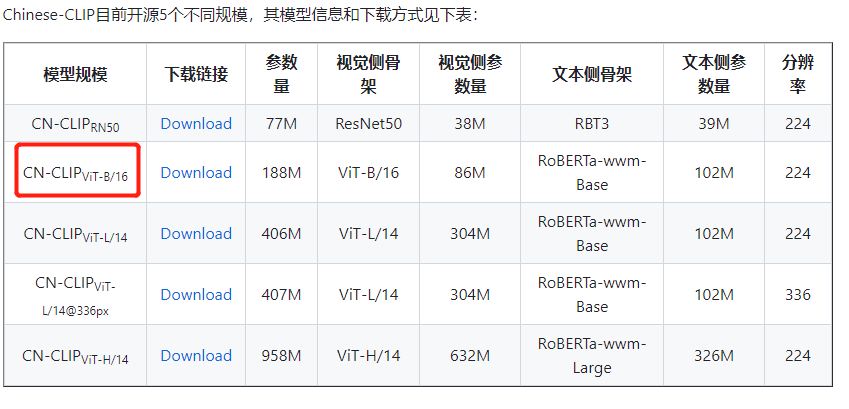
另外执行这一步会比较花时间,因为要下载模型。查看代码,实际上下载的模型是:ViT-B-16, 并且下载到了test文件夹中。
教程写得很详细,从环境搭建到模型测试步骤清晰明了,对初学者部署 Chinese CLIP 很有帮助,值得参考实践。访问我们的网站 Telkom University Jakarta